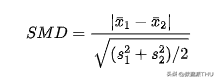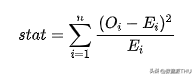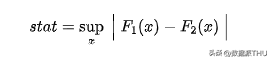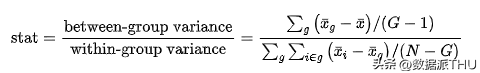|
在数据科学中,比力分歧组之间的变量的经历散布是一个常见的题目。出格是在因果揣度中,当我们需要评价随机化的质量时,这个题目经常出现。 当我们想评价某个政策(或用户体验特征、广告活动、药物等)的因果效应时,因果揣度中的黄金标准是随机对照实验(randomized control trials),也被称为A/B测试( A/B tests)。 在理论中,我们挑选一个样本停止研讨,并随机将其分为对照组(control)和尝试组(treatment),然后比力两个组之间的成果。随机化确保两个组之间唯一的区分是尝试,均匀而言,这样我们便可以将成果差别归因于尝试结果。 题目在于,虽然停止了随机化,但两个组永久不会完全不异。 但是,偶然它们甚至都不是“类似的”。 例如,一个组中能够有更多的男性或年长的人等。我们凡是称这些特征为协变量(covariates)或控制变量(control variables)。 当出现这类情况时,我们没法肯定成果差别仅仅是由于尝试致使的,而不能归因于不服衡的协变量。是以,在随机化以后,检查一切观察变量在各组之间能否平衡,而且能否没有系统性差别,是很是重要的。 另一种挑选是经过度层抽样来确保在先验条件下某些协变量是平衡的。 我们将斟酌两种分歧的方式,即可视化(visual)和统计方式(statistical)。 这两种方式凡是在直观性和松散性方面停止权衡:经过图表,我们可以快速评价和摸索差别,但很难肯定这些差别是系统性的还是由于乐音引发的。 文章来历: https://towardsdatascience.com/how-to-compare-two-or-more-distributions-9b06ee4d30bf 作者为 Matteo Courthoud 1. 示例先容让我们假定我们需要对一组个体停止尝试,并将他们随机分为尝试组和对照组。我们希望他们在尽能够多的方面类似,以便将两组之间的任何差别归因于尝试结果自己。我们还将尝试组分为分歧的分组,以测试分歧的尝试方式(例如同一药物的稍微变化)。 针对这个例子,我模拟了一个包括1000个个体的数据集,我们观察到其中一组特征。我从src.dgp导入了数据天生进程dgp_rnd_assignment(),还从src.utils导入了一些绘图函数和库。
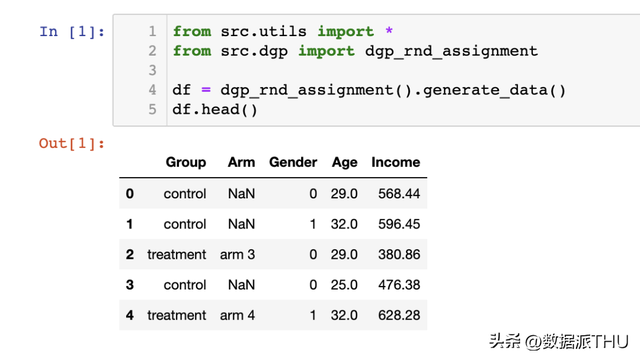
我们具有 1000 个个体的信息,我们观察到他们的性别、年龄和每周支出。每个个体被分派到尝试组或对照组,而且接管尝试的个体散布在四个尝试组中。 2. 两组对照—绘图(Plots)我们先从最简单的设备起头:我们想比力尝试组和对照组之间支出的散布。我们首先摸索可视化方式,然后再利用统计方式。第一种方式的上风是直观性,而第二种方式的上风是松散性。 在大大都可视化中,我将利用 Python 的 seaborn 库。 2.1 箱线图(Boxplot)第一种可视化方式是箱线图。 箱线图在总结统计和数据可视化之间获得了很好的平衡。箱子的中心代表中位数,鸿沟别离代表第一(Q1)和第三(Q3)四分位数。而箱线图的须(whiskers)则延长到离箱子内部跨越 1.5 倍四分位距(Q3 - Q1)的第一个数据点。落在须外的点会零丁绘制,凡是被以为是异常值(outliers)。
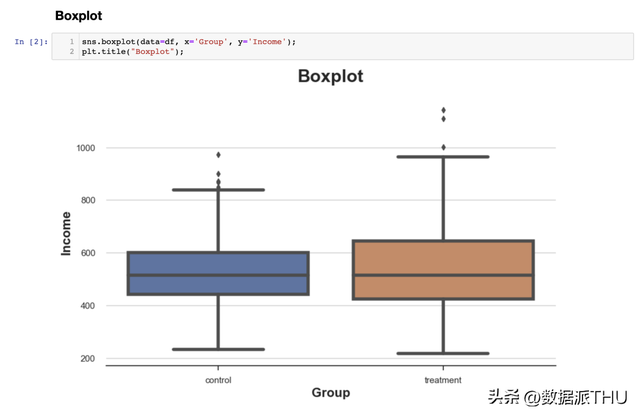
是以,箱线图既供给了总结统计信息(箱子和须),又供给了间接的数据可视化(异常值)。 尝试组的支出散布似乎稍微更分离:橙色的箱子更大,须覆盖的范围更广。但是,箱线图的题目在于它隐藏了数据的外形,只告诉我们一些总结统计信息,而不显现现实的数据散布。 2.2 直方图(Histogram)绘制散布最直观的方式是利用直方图。 直方图将数据分组到等宽的箱(bins)中,并绘制每个箱内的观察次数。
这个图表存在多个题目:
我们可以经过利用 stat 选项绘制密度而不是计数,并将 common_norm 选项设备为 False 来处理第一个题目,以零丁对每个直方图停止归一化。
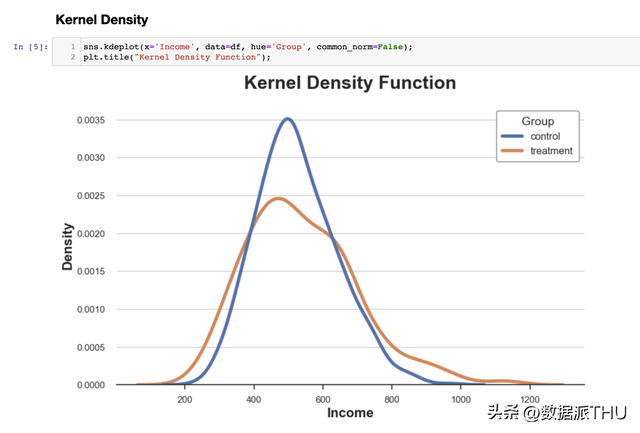
现在这两个直方图是可比力的! 但是,一个重要的题目照旧存在:箱子的巨细是肆意的。在极端情况下,假如我们将数据分组得较少,就会出现最多只要一个观察的箱子;假如我们将数据分组得更多,就会获得一个单一的箱子。在这两种情况下,假如我们过度夸大,图表将落空信息性。这是一个典范的误差-方差权衡(bias-variance trade-off)。 2.3 核密度估量(Kernel Density Estimation)一种能够的处理计划是利用核密度函数,它尝试用持续函数来近似直方图,称之为核密度估量(KDE)。
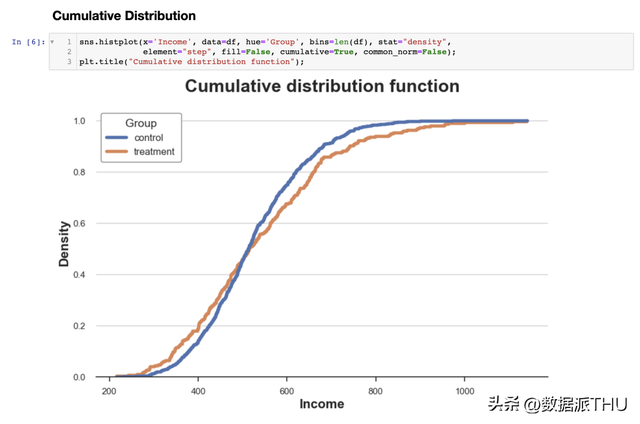
从图中可以看出,尝试组的支出估量核密度具有更"厚的尾部"(即方差较高),而均匀值在各组之间似乎类似。 核密度估量的题目在于它有点像黑匣子,能够袒护了数据的相关特征。 2.4 积累散布函数(Cumulative Distribution)两个散布的更通明的暗示是它们的积累散布函数。在 x 轴(支出)的每个点上,我们绘制了具有相称或更低值的数据点的百分比。积累散布函数的首要优点是:
我们若何解读这个图呢?
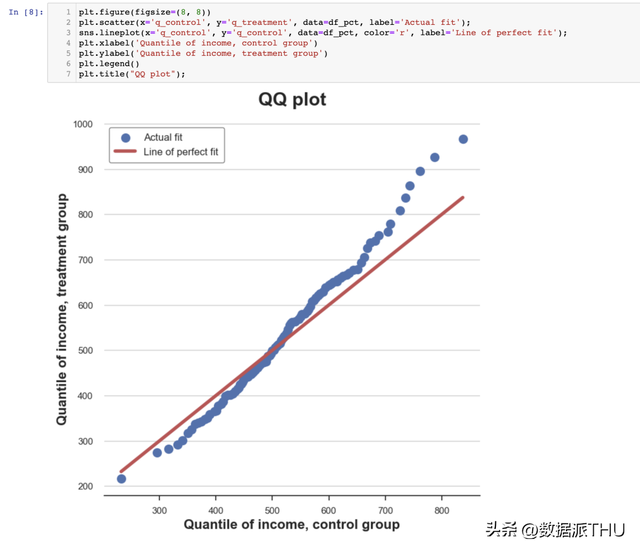
2.5 Q-Q图一个相关的方式是Q-Q 图,其中Q代表分位数。Q-Q图将两个散布的分位数相互绘制。假如两个散布不异,我们应当获得一条 45 度的线。 Python 中没有原生的 Q-Q 图函数,虽然 statsmodels 包供给了一个 qqplot 函数,但利用起来相对烦琐。是以,我们将手动绘制。 首先,我们需要利用百分位函数计较两组的四分位数。
现在我们可以将两个分位数散布相互绘制,并绘制 45 度线,代表完善拟合的基准。
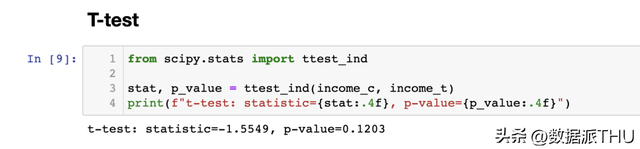
Q-Q 图对于积累散布图来说供给了很是类似的诠释。尝试组的支出具有不异的中位数(线在中心穿插),但尾部更宽(点在左端下方,在右端上方)。 3. 两组对照—检验(Tests)到今朝为止,我们已经看到了分歧的可视化方式来显现散布之间的差别。可视化的首要上风是直观性:我们可以经过目测差别并直观地评价它们。 但是,我们能够希望加倍松散,并尝试评价散布之间差别的统计明显性,即回答“观察到的差别是系统性的还是由于抽样噪声?”的题目。 现在,我们将分析分歧的检验方式来区分两个散布。 3.1 T检验(T-test)第一个也是最多见的检验是门生t检验。T检验凡是用于比力均值。在这类情况下,我们想要检验两个组之间的支出散布的均值能否不异。两个均值比力检验的检验统计量为: 其中 是样本均值, 是样本标准差。在一些温顺的条件下,检验统计量的渐近散布服从门生t散布。 我们利用 scipy 库的 ttest_ind 函数停止t检验。该函数返回检验统计量和响应的 值。
检验的 值为 0.12,是以我们不拒绝在尝试组和对照组之间均值无差别的原假定。
3.2 标准化均值差别(Standardized Mean Difference,SMD)凡是,当我们停止随机对照实验或 A/B 测试时,对尝试组和对照组之间一切变量的均值差别停止测试是一种杰出的做法。 但是,由于 t检验统计量的分母依靠于样本巨细,t检验因使得 值难以在分歧研讨间停止比力而遭到批评。现实上,我们能够在一个差别幅度很是小但样本量很大的尝试中获得明显成果,而在一个差别幅度很大但样本量很小的尝试中获得非明显成果。 一个被提出的处理计划是标准化均值差别(SMD)。 望文生义,这不是一个适当的检验统计量,而只是一个标准化的差别,可以计较为:
凡是,小于 0.1 的值被视为“小”的差别。 在停止 A/B 测试时,将尝试组和对照组之间一切变量的均匀值以及两者之间的间隔怀抱(不管是 t 检验还是 SMD)汇总到一个称为平衡表的表格中是一个好的做法。 我们可以利用 causalml 库中的 create_table_one 函数天生该表格。正如函数称号所示,平衡表应当是在停止 A/B 测试时首先显现的表格。
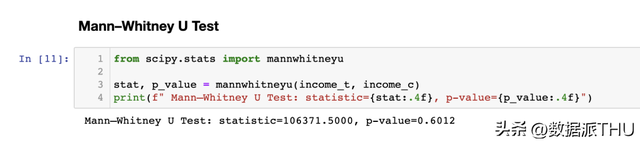
在前两列中,我们可以看到尝试组和对照组之间分歧变量的均匀值,括号内为标准误差。在最初一列中,SMD 的值对应的标准化差别对于一切变量都大于 0.1,表白这两组能够存在差别。 3.3 Mann–Whitney U 检验另一种替换的检验是 Mann–Whitney U 检验。该检验的零假定(null hypothesis)是两组具有不异的散布,而备择假定(alternative hypothesis)是一组的值比另一组更大(或更小)。 与我们之前见过的其他测试分歧,Mann–Whitney U 检验不受异常值的影响,而是集合在散布的中心。 检验步调以下:
在零假定下,即两个散布之间没有系统的排名差别(即不异的中位数),检验统计量的渐近正态散布具有已知的均值和方差。 计较 和 的背后的直觉是:假如第一个样本中的值都大于第二个样本中的值,则 ,是以 将为零(最小可达值)。否则,假如两个样底细似, 和 将很是接近于 (最大可达值)。 我们利用 scipy 库的 mannwhitneyu 函数停止测试。
我们获得一个 值为 0.6,这意味着我们不拒绝支出散布在尝试组和对照组中不异的零假定。
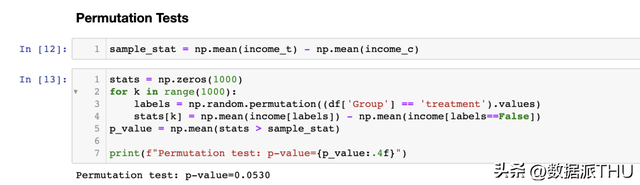
3.4 置换检验(Permutation Tests)非参数的另一种挑选是置换检验。 其思惟是,在零假定下,两个散布应当是不异的,因打乱(shuffling)组标签不会明显改变任何统计量。 我们可以挑选任何统计量,并检查原始样本中该统计量的值与组标签排列的散布相比若何。例如,让我们将样本均值之差作为测试统计量。
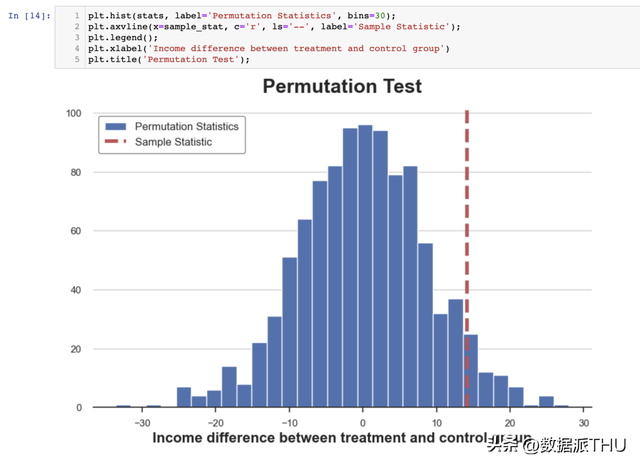
置换检验给出的 值为 0.053,在 5%的明显性水平下稍微不拒绝零假定。 我们若何诠释 值呢?这意味着数据中的均值差别大于 1-0.053=94.4%的置换样本均值差别。 我们可以经过将测试统计量在置换样本中的散布与其样本值停止绘图来可视化测试成果。
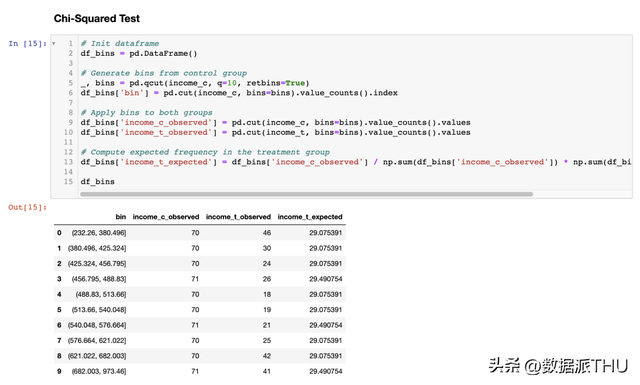
正如我们所看到的,样本统计量在置换样本中的值相对来说很是极端,但并不外分。 3.5 卡方检验(Chi-Squared Test)卡方检验是一种很是强大的检验方式,首要用于测试频次的差别。 卡方检验的其中一个较少被人领会的利用是测试两个散布之间的类似性。其思惟是将两个组的观察值分组。假如两个散布是不异的,我们期望每个组中的观察频数不异。重要的是,我们需要每个组中有充足的观察值,以使检验有用。
我将天生与对照组中支出散布的非常位数对应的分组,并计较假如两个散布不异,则尝试组中每个分组中预期的观察数目。
现在我们可以经过比力尝试组中观察到的观察数目( )和预期观察数目( )来停止检验,别离对应于每个分组。检验统计量由下式给出:
其中,分组由 索引, 是分组 中观察到的数据点数, 是分组 中预期的数据点数。由于我们利用对照组中支出散布的非常位数天生了这些分组,我们期望尝试组中每个分组中的观察数目在各个分组中不异。检验统计量在渐近情况下服从卡方散布。 为了计较检验统计量和检验的 值,我们利用 scipy 中的 chisquare 函数。
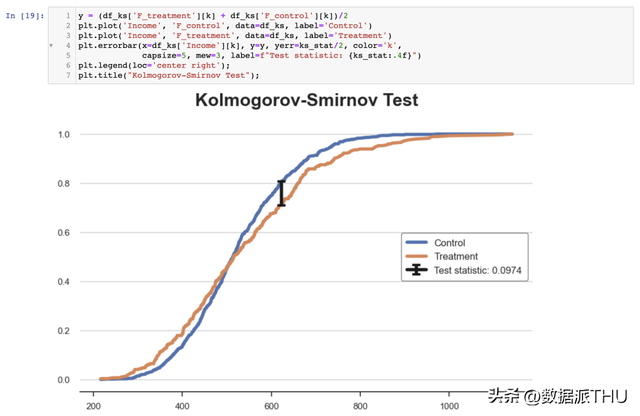
与迄今为止的一切其他测试分歧,卡方检验激烈拒绝了两个散布不异的零假定。 为什么会这样? 缘由在于两个散布具有类似的中心但分歧的尾部,而卡方检验测试的是全部散布的类似性,而不但仅是中心,这与我们之前的测试分歧。 这个成果告诉我们一个警示故事:在从 值中得出自觉结论之前,领会自己现实在测试什么很是重要! 3.6 Kolmogorov-Smirnov 检验Kolmogorov-Smirnov 检验能够是比力散布的最常用的非参数检验。 Kolmogorov-Smirnov 检验的思惟是比力两个组的积累散布。出格地,Kolmogorov-Smirnov 检验统计量是两个积累散布之间的最大绝对差别。 Kolmogorov-Smirnov 检验统计量公式以下:
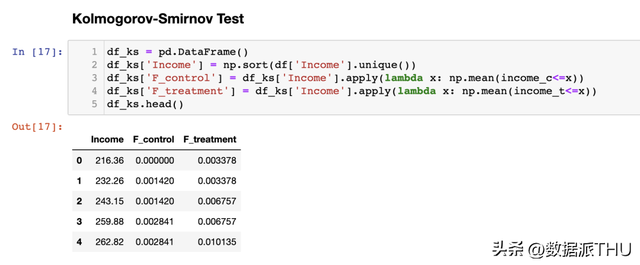
其中 和 是两个积累散布函数, 是底层变量的值。Kolmogorov-Smirnov 检验统计量的渐近散布是 Kolmogorov 散布。 为了更好地了解这个检验,让我们绘制积累散布函数和检验统计量。首先,我们计较积累散布函数。
我们现在需要找到积累散布函数之间绝对间隔最大的点。
我们可以经过绘制两个积累散布函数和检验统计量的值来可视化检验统计量的值。
从图中可以看出,检验统计量的值对应于在支出约为 650 时两个积累散布之间的间隔。在阿谁支出值下,我们可以看到两个组之间的不服衡最大。 我们现在可以利用 scipy 的 kstest 函数履行现实的检验。
值低于 5%:我们以 95%的置信度拒绝了两个散布不异的零假定。
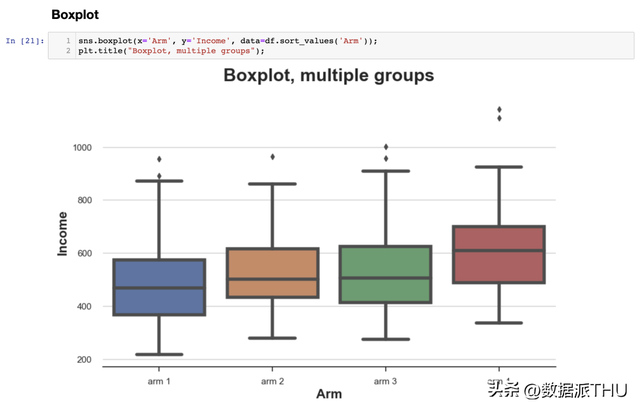
4. 多组-绘图(Plots)到今朝为止,我们只斟酌了两组的情况:尝试组和对照组。 但假如我们有多个组呢?我们上面先容的一些方式可以很好地适用于多个组,而其他方式例不可。 作为一个工作示例,我们现在要检查在分歧的尝试计划中支出散布能否不异。 4.1 箱线图(Boxplot)当我们有几个组时,箱线图可以很好地扩大,由于我们可以将分歧的箱子(box)并排放置。
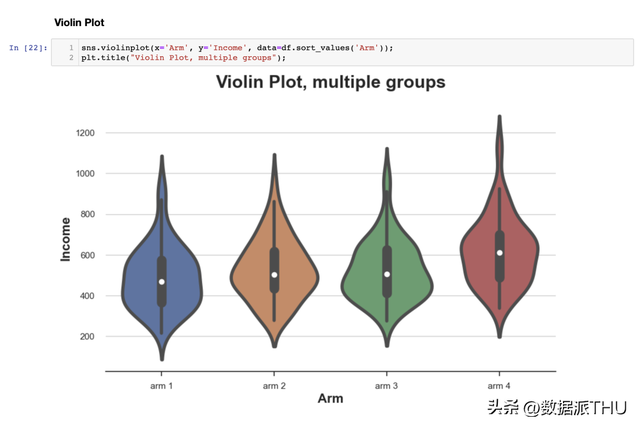
从图中可以看出,在分歧的尝试计划中,支出散布似乎是分歧的,较高编号的计划具有较高的均匀支出。 4.2 小提琴图(Violin Plot)小提琴图是箱线图的一个很好的扩大,它连系了摘要统计和核密度估量。小提琴图沿着 轴显现零丁的密度图,使它们不会堆叠。默许情况下,它还在内部增加了一个小型箱线图。
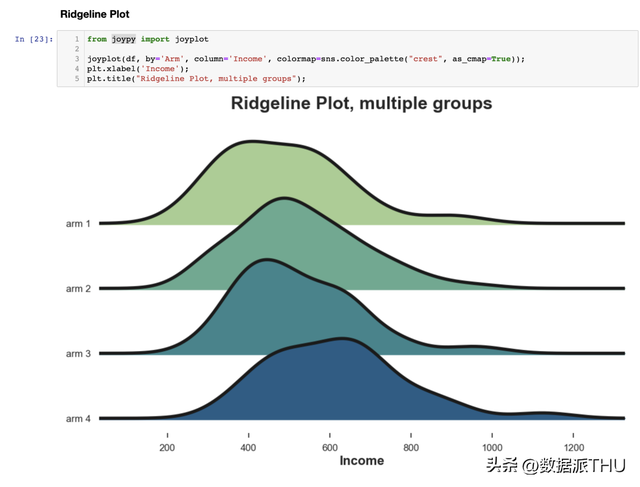
与箱线图类似,小提琴图表白在分歧的尝试计划中,支出是分歧的。 4.3 山脊图(Ridgeline Plot)最初,山脊图沿 轴绘制多个核密度散布,使它们比小提琴图更直观,但部分堆叠。 不幸的是,matplotlib 和 seaborn 中都没有默许的 Ridgeline 图。我们需要从 joypy 导入它。
再次,Ridgeline 图表白较高编号的尝试计划具有较高的支出。从这个图中,我们也更轻易看出散布的分歧外形。 5. 多组-检验最初,让我们斟酌用于比力多个组的假定检验。为简单起见,我们将集合会商最风行的假定检验方式:F 检验。 5.1 F检验在多组情况下,最多见的检验方式是 F检验。 F 检验用于比力分歧组之间变量的方差。这类分析也称为方差分析(ANOVA)。 现实上,F 检验统计量以下所示:
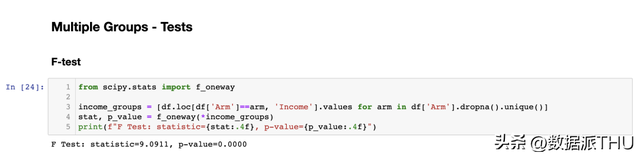
其中 是组的数目, 是观察数目, 是整体均值, 是组 内的均值。在组自力的零假定下,F 统计量服从 F 散布。
检验的 值接近于零,暗示我们激烈拒绝了在分歧尝试计划之间支出散布无差别的零假定。 6. 结论本文先容了很多分歧的方式来比力两个或多个散布,我们看到了分歧的方式能够更适用于分歧的情况。可视化方式对于建立直观了解很是有用,但统计方式对于决议相当重要,由于我们需要可以评价差别的巨细和统计明显性。 希望本文对列位的科研工作有所帮助。 获得本文材料,请关注微信公众号数据派THU至背景答复“20230527”停止下载。 参考文献 [1] Student, The Probable Error of a Mean (1908), Biometrika. [2] F. Wilcoxon, Individual Comparisons by Ranking Methods (1945), Biometrics Bulletin. [3] B. L. Welch, The generalization of “Student’s” problem when several different population variances are involved (1947), Biometrika. [4] H. B. Mann, D. R. Whitney, On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other (1947), The Annals of Mathematical Statistics. [5] E. Brunner, U. Munzen, The Nonparametric Behrens-Fisher Problem: Asymptotic Theory and a Small-Sample APProximation (2000), Biometrical Journal. [6] A. N. Kolmogorov, Sulla determinazione empirica di una legge di distribuzione (1933), Giorn. Ist. Ital. Attuar.. [7] H. Cramér, On the composition of elementary errors (1928), Scandinavian Actuarial Journal. [8] R. von Mises, Wahrscheinlichkeit statistik und wahrheit (1936), Bulletin of the American Mathematical Society. [9] T. W. Anderson, D. A. Darling, Asymptotic Theory of Certain “Goodness of Fit” Criteria Based on Stochastic Processes (1953), The Annals of Mathematical Statistics. |
")
一年级下册(新人教部编版)数学、语文全套复习资料一年级的孩子语文、数学、英语、科
")
需要的朋友可以下载关注私信”56“或者“验收表格”会自动回复下载链接需要的朋友可以

高薪水电工必备!442页水电安装工程内业资料全套范例,附最新表格建筑工程项目施工过

零件图的视图该怎么选择、尺寸如何布置,待会你就明白了零件典型结构的尺寸标注,共91
")
华为的人力资源管理赫赫有名,尤其是在薪酬绩效管理方面,华为更是处于领先地位,他们
(可下载可在线学习)")
每天都有很多粉丝留言咨询资料问题,由于人数太多老师们回复不过来,头条发的每一份资
")
食用菌类和植物干货日本花菇▼日本花菇日本花菇是上等的冬菇,肉厚、圈口紧卷、菇面绽

1.《零基础学AE》免费,观看途径:1.腾讯网课;2.直线网2.《零基础学C4D》免费,观看

每日晨读资料汇总,有孩子的家长火速收藏!作文水平越来越好!

2020年10月初的时候,调研君跟一钻研阿米巴经营模式多年的朋友,为一家集团公司做阿米

众所周知,我是一个爱学习的人。今天就给大家分享分享我的百度云学习资源。这是一个功

建筑工程资料是记载建筑工程施工全过程的一项重要内容,是指在建筑施工过程中直接形成
,填表指南和样板,请收藏")
本资料为房建全套施工过程资料(共636页),doc格式;每个地方的表格和要求不一样,此

建筑工程施工资料填写范本全套,检验批质量验收表格(已分类)及填写注意事项,可下载

倪海厦全套视频学习资料+100多套珍藏书籍,全部可分享!另外还有100多套珍贵中医书籍

近日,中科院因高额费用停用知网,引发热议。论文还没写完,为找不到资料发愁?别怕,

一建【工程法规】是一级建造师考试科目知识点最零碎的科目,虽然没有主观题,但各种各
新产品开发及项目管理(PPT50页资料精品)")
见文章最后源文件获取方式每周的资料分享,今天给大家分享汽车(丰田)新产品开发及项
")
豆类制品及果仁绿豆▼绿豆绿豆绿豆是蝶形花科绿豆属一年生草本植物,学名Vigna radiat

点上方“design小徐”关注,看更多精彩内容!「分 享」「分 享」干货资料 室内设计大
声明:本站内容由网友分享或转载自互联网公开发布的内容,如有侵权请反馈到邮箱 1415941@qq.com,我们会在3个工作日内删除,加急删除请添加站长微信:15314649589
Copyright @ 2022-2044 杭州共生网络 www.gongshengyun.cn Powered by Discuz!