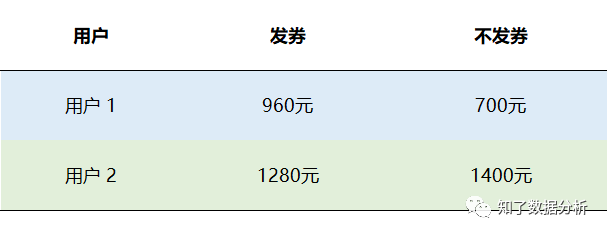
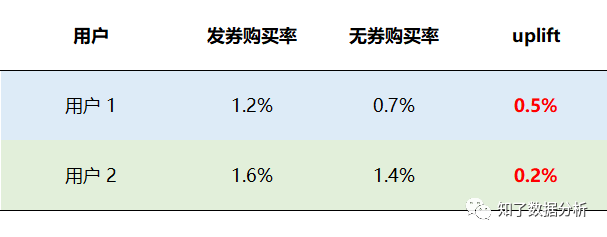
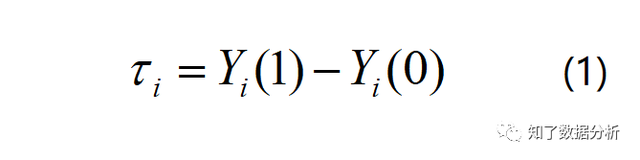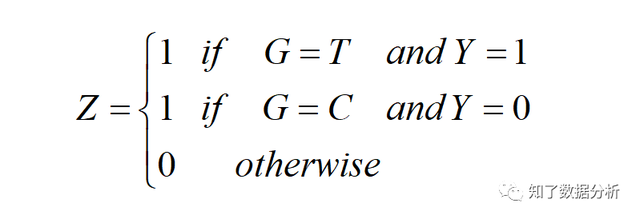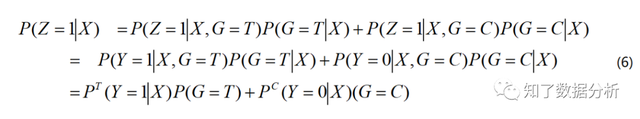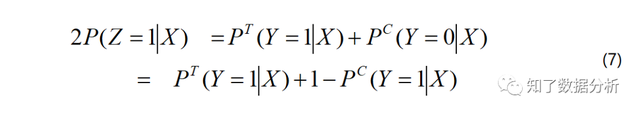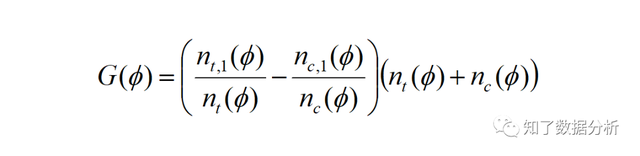布景:题目先行假定我们现在要搞一个优惠券促销活动,经过历史数据猜测了两类用户发券采办率和无券采办率的成果(见下图),接下来我们想要对用户发放优惠券,这时会面临一个必必要处理的题目:给哪类用户发放优惠券可以使总收益最大化呢?
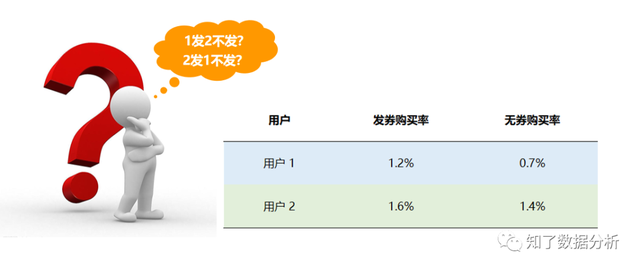
01 什么是增益模子(uplift model)想要晓得应当给哪一类用户发放优惠券,我们需要搞清楚哪一类用户对优惠券刺激最敏感,换言之,也就是需要对用户停止分类,领会每一类用户的特点。在营销活动中,对用户停止自动干涉称为treatment,例如发放优惠券是一次treatment。按照能否对用户停止干涉以及干涉成果,我们可以将用户分为以下四类:
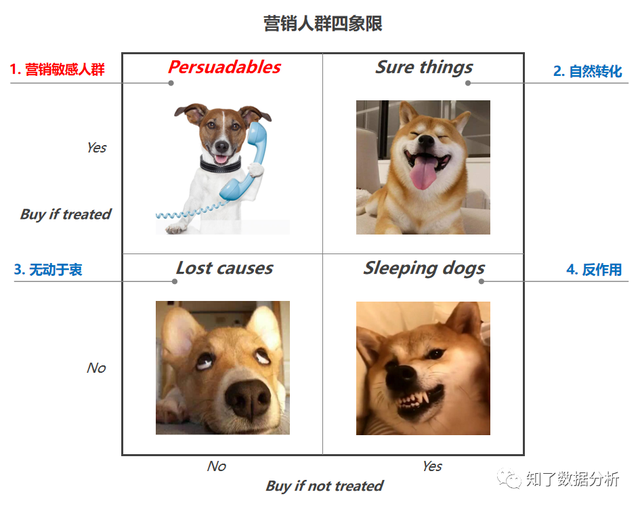
对发放优惠券这类有本钱的营销活动,我们不成能对一切用户都发放补助,这个本钱是任何企业都没法承受的。斟酌到每个用户对价格的接管水平是纷歧样的,按照“营销四象限人群”散布,我们希望模子触达的是营销敏感的用户,即经过发放优惠券促进用户采办,而对于其他用户,最好不要发券,这样才能最洪流平的节省本钱。 我们再来看布景中的小例子,用户2发券后采办率(1.6%)明显高于用户1(1.2%),似乎我们应当对用户2发放优惠券,更能刺激其发生采办。但究竟真的是这样吗? 假定用户1和用户2各1000人,不发券产物价格是100元,发放优惠券后价格是80元,我们可以有四种计划:用户1和2都发放优惠券、用户1和2都不发放优惠券、1发2不发、2发1不发。我们别离来计较一下这四种计划带来的总收益:
经过计较四种计划的收益,我们发现现真相况和料想的并纷歧样,给发券采办率更高的用户2发放优惠券反而收益是最低的,这是为什么呢? 我们来进一步分析一下,除了发券采办率之外,我们还能晓得这两类用户在没有优惠券情况下的自然采办率,按照这两个数据可以计较动身放优惠券所带来的增量功效。用户1的发券采办率虽然低,但在没有优惠券刺豪情况下的采办率更低,即优惠券所带来的增量反而是比用户2更高,而我们做营销活动的目标是最大化整体的收益,本质是最大化优惠券的增量,是以我们应当向用户1发放优惠券。
经过这个小例子,我们可以获得一个结论:响应模子(reponse model)可以猜测用户的采办几率,可是该模子不能告诉我们这批人能否由于发放优惠券而发生采办,这样我们就没法区分营销敏感(Persuadables)和自然转化(Sure things)这两类人群。也就是说响应模子(reponse model)很有能够会误导我们做出毛病的决议。
而增益模子(uplift model)要做的就是帮助我们找到这些营销敏动人群,正确判定营销干涉所带来的“增量提升”,从而促使营销推行效力的最大化,而不是把营销预算浪费在“原本就会转化”的那部分人身上。假如用一句话总结增益模子(uplift model):经过用户分群的方式对用户停止邃密化运营的一种科学手段。
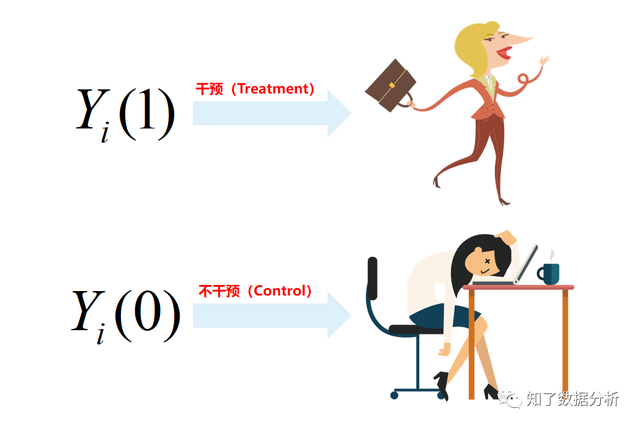
为了帮助大师更好的了解增益模子,我们机关这样一个场景:假定有N个用户,Yi(1)暗示我们对用户i干涉后的成果,比如给用户i发放优惠券后(干涉)用户下单(成果),Yi(0)暗示没有对用户干涉的情况下用户的输出成果,比如没有给用户i发放优惠券(干涉),用户下单(成果)。以下图所示:
那末,用户i的因果效应(causal effect)的计较以下:
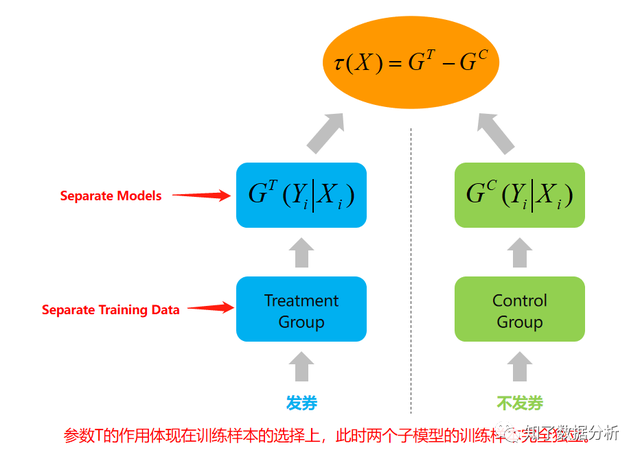
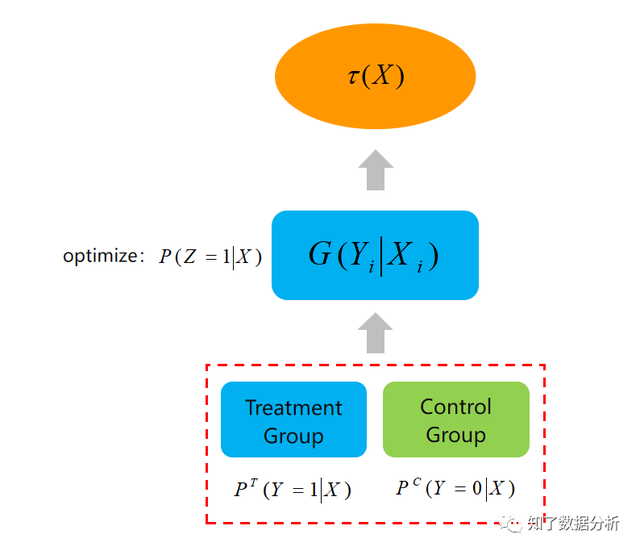
增益模子的方针就是最大化这个增量,即有干涉战略相对于无干涉战略的提升,简单讲就是干涉前后成果的差值。现实利用时会取一切用户的因果效应期望的估量值来权衡全部用户群的结果,称为条件均匀因果效应(Conditional Average Treatment Effect, CATE)。 上式中Xi是用户i的特征,所谓的conditional指基于用户特征。 (2)式是理想的增益模子计较形式,现实上,对一个用户i我们不成能同时观察到利用战略(treatment)和未利用战略(control)的输出成果,即不成能同时获得Yi(1)和Yi(0)。由于对某个用户,我们要末发优惠券,要末不发。所以,我们可以将(2)式点窜成: 其中Yi(obs)是用户i可以观察到的输出成果,Wi是一个二值变量,假如对用户i利用了战略,Wi=1,否则Wi=0。 在条件自力的假定下,条件均匀因果效应的期望估量值是: 上式要满足条件自力(CIA)的条件,即用户特征与干涉战略是相互自力的。 增益模子要优化τ(Xi),值越高越好。但是一个用户不能同时观察到利用干涉战略和不利用干涉战略的成果,是以τ(Xi)是难以间接优化的。但假如经过AB尝试,可以获得利用干涉战略和不利用干涉战略两组人群,假如两组人群的特征散布分歧,可以经过模拟两组人群的τ(Xi)获得个体用户的τ(Xi)。是以增益模子依靠AB尝试的数据。 需要说明的一点是,增益模子(uplift model)是一组用于不异目标的建模方式的总称。下面就给小伙伴们先容三种常用的增益模子建模方式。 02 常用uplift建模方式2.1 双模子(Two Model, T-Learner)模子公式1:
建模进程: 以优惠券发放为例,方针是用户能否下单。练习时取尝试组的用户练习,正样本是下单用户,负样本是未下单用户,猜测成果是每个用户下单的几率。类似地,对照组也可以利用另一个模子猜测出每个用户下单的几率。两个组的用户下单几率求均匀,即可获得: 两者相减即获得τ(X)。猜测时,对用户别离利用G(T)和G(C)猜测,两个模子猜测的分数相减即获得猜测用户i的τ(Xi),最初按照τ(Xi)的凹凸决议能否发券。
模子优点:
模子弱点:
2.2 差分响应模子升级版(One-Model, APProach)模子公式2:
建模进程: 差分响应模子的练习数据和模子都是各自自力的,可以别离在练习数据层面上买通以及在模子层面上买通,获得升级版的差分响应模子。 在尝试组和对照组的用户特征中,加入与T有关的特征,实现数据层面的买通,即尝试组和对照组合并,利用同一个模子练习。猜测时将同一样本特征停止屡次输入,每次只是改变分歧的T值。这是阿里大文娱提到的一种方式。
模子优点:
模子弱点:
2.3 Class TransformationMethod别的一种更松散的可以实现尝试组对照组数据买通和模子买通的方式叫做class transformation method,可以间接优化τ(Xi)。 模子公式界说一个变量G∈{T, C},G=T暗示有干涉,即尝试组(treatment),G=C暗示无干涉,即对照组(control)。uplift分数τ可以暗示为:
为了同一暗示尝试组和对照组都下单的情况(Y=1),再界说一个变量Z,Z∈{0, 1}:
下面证实优化(5)式相当于优化P(Z=1∣X)。 假定干涉战略G与用户特征X相互自力,即G自力于X:P(G∣X)=P(G),(5)式可以转写为:
留意到P(G=T)和P(G=C)是可以经过AB尝试控制的,在随机化尝试中,假照尝试组和对照组的人数是相称的,那末P(G=T)=P(G=C)=1/2,即一个用户被分在尝试组(有干涉战略)和被分在对照组(无干涉战略)的几率是相称的。 在该假定下,(6)式可以改写为:
由(7)式可得:
(8)式就是要计较的uplift score,此时只要Z一个变量,可以间接对Z=1建模,相当于优化P(Z=1∣X),而不需要别离对尝试组P(T)和对照组P(C)零丁建模。而P(Z=1∣X)可以经过任何分类模子获得,所以这个方式称为Class Transformation Method。 现实上,Z=1就是尝试组中下单的用户和对照组中未下单的用户,是以可以间接将尝试组和对照组用户合并,利用一个模子建模,实现了数据层面和模子层面的买通。猜测时,模子猜测的成果就是uplift score,这点与差分响应模子分歧。
该方式需满足以下两个假定:
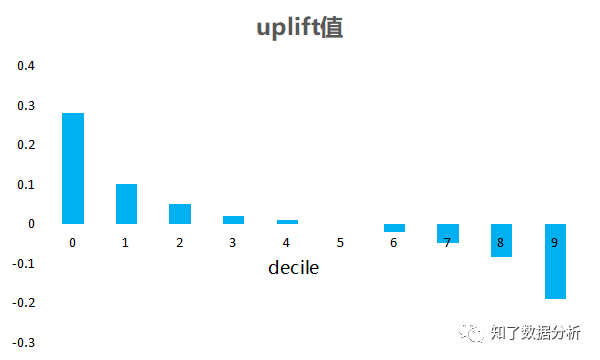
03 若何评价uplift模子按照uplift模子的界说,uplift score得分越高,代表该用户增益就越大。但由于增益模子中不成能同时观察到同一用户在分歧干涉战略下的响应,是以没法间接计较上述评价目标。增益模子凡是都是经过分别非常位数(decile)来对齐尝试组和对照组数据从而停止间接评价,而不是在一个测试集上间接评价。 接下来首要给家先容三种首要的评价方式。 3.1 uplift 柱状图测试集上,尝试组和对照组的用户别离依照uplift由高到低排序,分别为十等份,即非常位(decile),别离是Top 10%、Top 20% …… Top 100%用户。别离对尝试组和对照组中每个非常位内的用户求E[Y(T)∣X(T)] 和E[Y(C)∣X(C)],即猜测分数的均值,然后相减,作为这个非常位bin内的uplift,绘制柱状图,以下图:
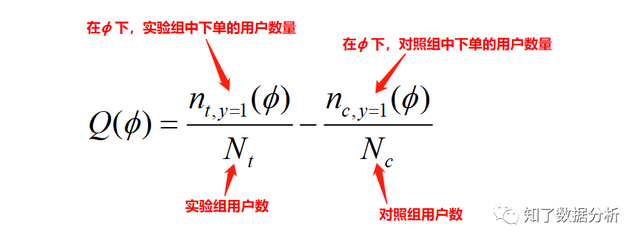
这类方式只能定性分析,没法计较出一个具体的值来整体评价模子的黑白。 3.2 Qini曲线(Qini curve)可以在uplift bars的根本上绘制曲线,类似AUC来评价模子的表示,这条曲线称为Qini curve,计较每个百分比的Qini系数,最初将这些Qini系数毗连起来,获得一条曲线。Qini系数计较以下:
ϕ是依照uplift score由高到低排序的用户数目占尝试组或对照组用户数目的比例,如ϕ=0.1,暗示尝试组或对照组中前10%的用户。
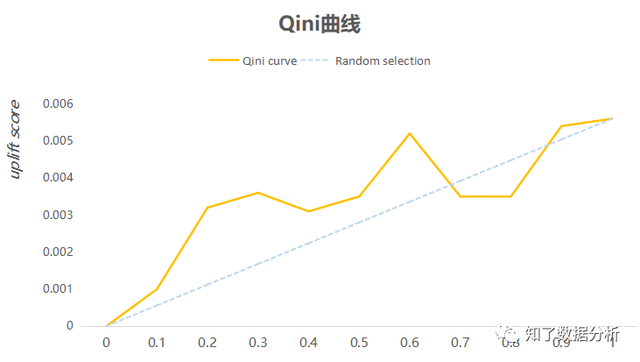
如上图,蓝色是随机曲线,橙色是Qini曲线,Qini曲线与随机曲线之间的面积作为评价模子的目标,面积越大,暗示模子成果远跨越随机挑选的成果,与AUC类似,这个目标称为AUUC(Area Under Uplift Curve)。可以看到,当横轴即是0.6时,对应的纵轴大如果0.0052(uplift score),暗示当uplift score即是0.0052时,可以覆盖前60%的用户数目,这部分用户就是营销活动的方针用户(persuadables)。 Qini系数分母是尝试组和对照组的全部用户数,假如两组用户数目不同比力大,就会致使成果目标失真。另一种积累增益曲线可以避免这个题目。 3.3积累增益曲线(Cumulative Gain curve)积累增益曲线计较以下:
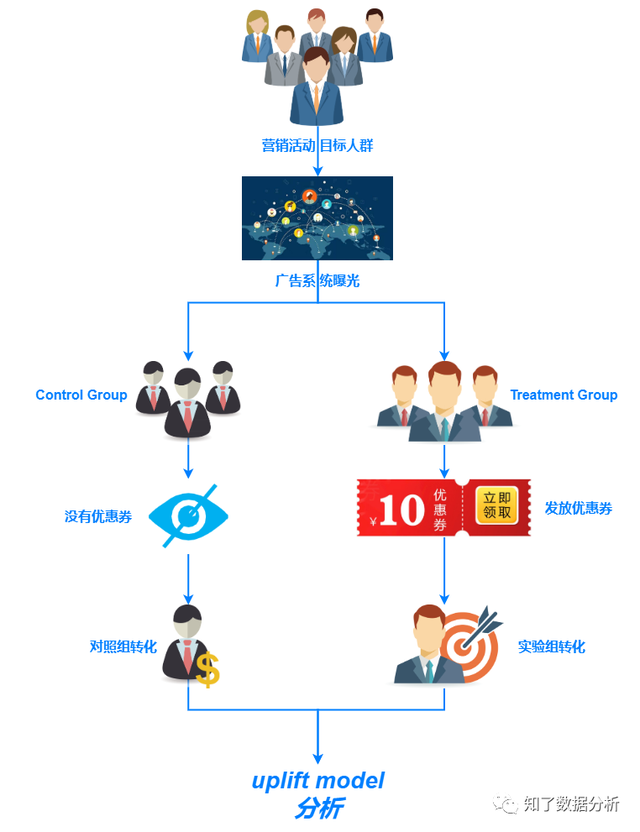
该公式中各标记寄义与Qini系数标记寄义不异。与Qini系数相比,积累增益的分母是百分比ϕ下的尝试组或对照组人数,并乘以nt(ϕ)+nc(ϕ)作为全局调剂系数,避免尝试组和对照组用户数目不服衡致使的目标失真题目。 04 uplift精准营销流程最初,我们经过下面这张图直观的总结一下,在现实工作中是若何经过uplift模子停止精准营销的:
本文由 @知了数据分析 原创公布于大家都是产物司理。未经答应,制止转载。 题图来自Unsplash,基于CC0协议。 该文概念仅代表作者本人,大家都是产物司理平台仅供给信息存储空间办事。 |